

LLM Pricing vs Performance
How enterprises can navigate the shifting trade-offs between cost, accuracy, and speed in large language models

Why LLM Economics Are the New Frontier

Over the past year, the economics of large language models (LLMs) have shifted dramatically. What used to be a market dominated by a few premium players like OpenAI and Anthropic is now being reshaped by cost-efficient disruptors such as DeepSeek R1 and Google’s Gemini Flash models.
Enterprises are no longer asking “Which model is best?” but rather “Which model delivers the best value for my use case?”
This article dives into the pricing mechanics, benchmark comparisons, and strategic implications for teams navigating the LLM landscape. We’ll go beyond marketing claims and leaderboard screenshots to unpack the real trade-offsbetween cost, accuracy, latency, and reasoning depth.
The Fundamentals of LLM Pricing

Most commercial LLMs charge by tokens, the atomic unit of text.
Input tokens = the words you send to the model (your prompt)
Output tokens = the words the model generates back
Providers vary widely:
Gemini 2.5 Pro → $2.50 input / $15 output (per 1M tokens)
OpenAI o3 → $10 input / $40 output
DeepSeek R1 → $0.10 input / $0.40 output
The difference between DeepSeek and OpenAI is not 2x or 3x — it’s 100x in some configurations.

On top of raw cost, you must factor in context windows (the maximum length of input + output). Leading models offer anywhere from 128k to 1M+ tokens. Exceeding these windows results in truncated outputs — a hidden cost many teams discover too late.
Lesson: Token efficiency and model selection are as important as negotiating provider discounts.
Reasoning vs Non-Reasoning Models

A second pricing layer comes from reasoning models — systems designed to “think” longer before responding.
Reasoning models (e.g., OpenAI o1/o3, Anthropic Claude Sonnet 3.7 Thinking, DeepSeek R1)
Backtrack and deliberate
Deliver higher accuracy in coding, math, and analytics
Consume 30–300% more tokens (hidden cost)
Non-reasoning models (e.g., Gemini Flash, GPT-4o standard, Mistral)
Faster, cheaper
Strong enough for conversation, summarization, and light coding
The trade-off: You pay more tokens for reasoning, but it can mean the difference between a correct solution and a hallucination in high-stakes tasks.
Benchmark Snapshots: Who Wins Where?
Different models dominate different benchmarks.
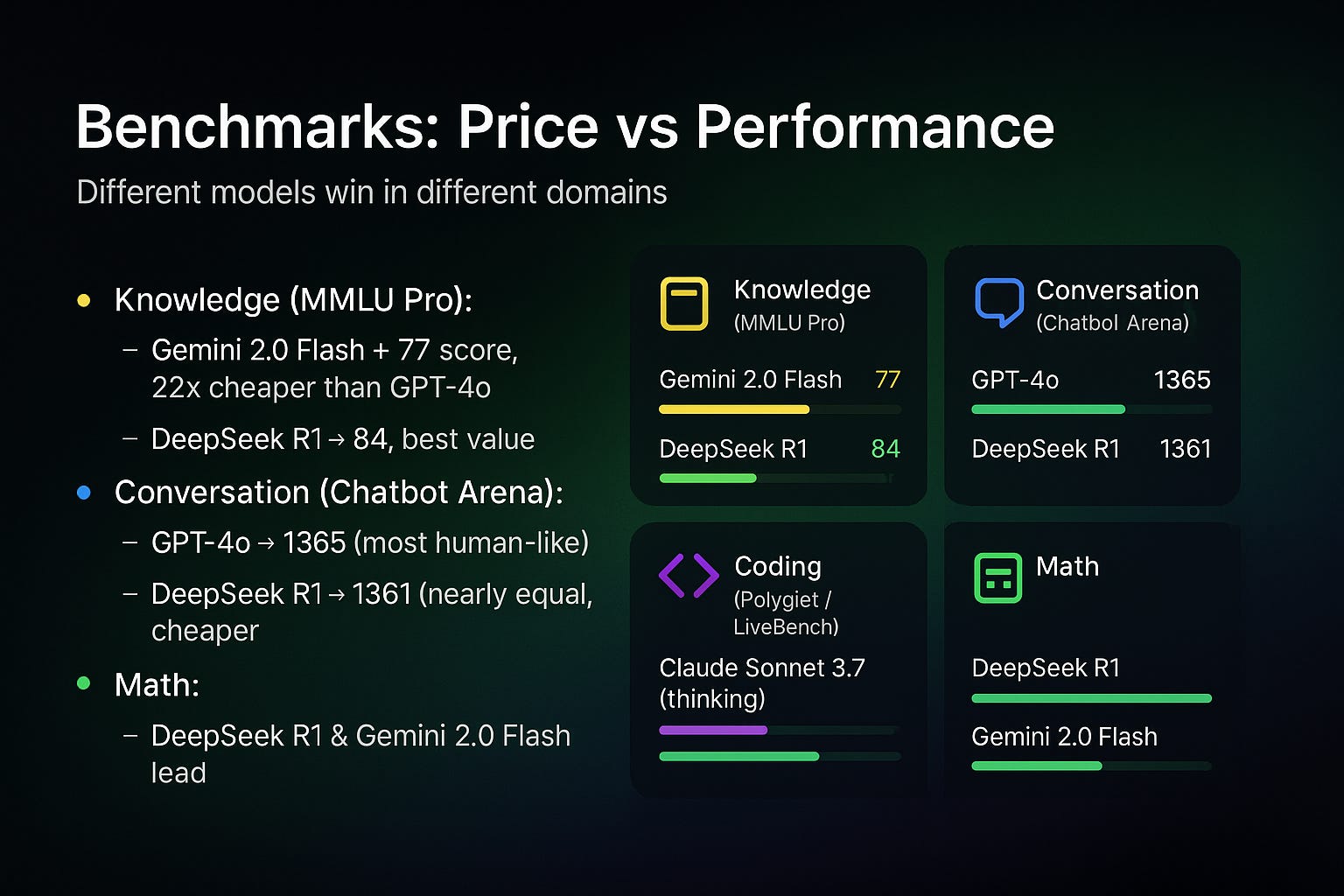
1. Knowledge (MMLU Pro)
Gemini 2.0 Flash → 77 score, 22× cheaper than GPT-4o
DeepSeek R1 → 84, best value across cost and accuracy
2. Conversational Quality (Chatbot Arena)
GPT-4o → 1365 (most human-like)
DeepSeek R1 → 1361 (nearly identical, far cheaper)
3. Coding (Polyglot & LiveBench)
Claude Sonnet 3.7 (thinking) → 64.9% accuracy, current leader
DeepSeek R1 → competitive at a fraction of the cost
OpenAI o3 → strong, but expensive
4. Math & Analytics (LiveBench)
DeepSeek R1 → outperforms OpenAI in many cases
Gemini 2.0 Flash → strong, especially given it’s not fully reasoning-based
Lesson: There is no single “best” LLM. The right model depends on whether you’re building a chatbot, writing code, or solving complex math.
The Price vs Performance Map

When you map cost per million tokens against benchmark performance, four patterns emerge:
Top Value:
DeepSeek R1
Gemini 2.0 Flash
Premium Accuracy:
OpenAI o3
Claude Sonnet 3.7 Thinking
Balanced Choice:
GPT-4o
Lagging Models:
Claude Haiku / Opus (high cost, weaker scores)
This landscape highlights how cost disruptors (DeepSeek, Gemini Flash) are forcing premium providers to justify higher price points with niche reasoning gains.
Strategic Implications for Enterprises

Here’s how enterprises should approach LLM selection today:
Conversational bots → GPT-4o, Gemini Flash, DeepSeek R1
Coding assistants → Claude Sonnet 3.7 (thinking), OpenAI o3
Math/Analytics → DeepSeek R1, Gemini Flash
Knowledge Q&A → Gemini Flash (low cost, strong MMLU Pro)
General balance → GPT-4o (premium but versatile)
Don’t lock yourself into a single vendor. The winning model will change quarterly as prices and benchmarks shift.
Recommendations

Pilot multiple models through orchestration tools like OpenRouter
Set max token limits to control runaway costs
Use reasoning selectively (math, code debugging, analytics)
Default to cost-efficient models (DeepSeek R1, Gemini Flash)
Reassess quarterly as benchmarks and pricing evolve
The key is governance. Cost savings and performance gains don’t come from picking the “right” model once — they come from systematic benchmarking and model orchestration.
Closing Insights

The LLM market is not just about who is smartest but about who is smartest at the right price.
Don’t overpay for marginal accuracy gains.
Match model strengths to specific workflows.
Embrace DeepSeek and Gemini Flash for cost-performance leadership.
Leverage OpenAI and Anthropic for premium reasoning tasks.
Treat benchmarking as a continuous process, not a one-off exercise.
Final note: The LLM race is dynamic. The advantage goes to organizations that adapt their pricing + performance choices faster than competitors.
Further Resources
AIMultiple — LLM Pricing: Top 15+ Providers Compared (Cem Dilmegani, 2025)
Data Science Collective — Economics of LLMs: Evaluations vs Pricing (Ida Silfverskiöld, 2025)
ArtificialAnalysis.ai — Real-time leaderboard data for LLM benchmarks
MMLU Pro, Chatbot Arena, LiveBench — Leading independent evaluation datasets