

Meta’s Superintelligence Gamble
Scale AI, Billion-Dollar Offers and the War for Talent

Introduction: When Capital Meets Conviction

2025 may be remembered as the year Meta stopped chasing—and started swinging.
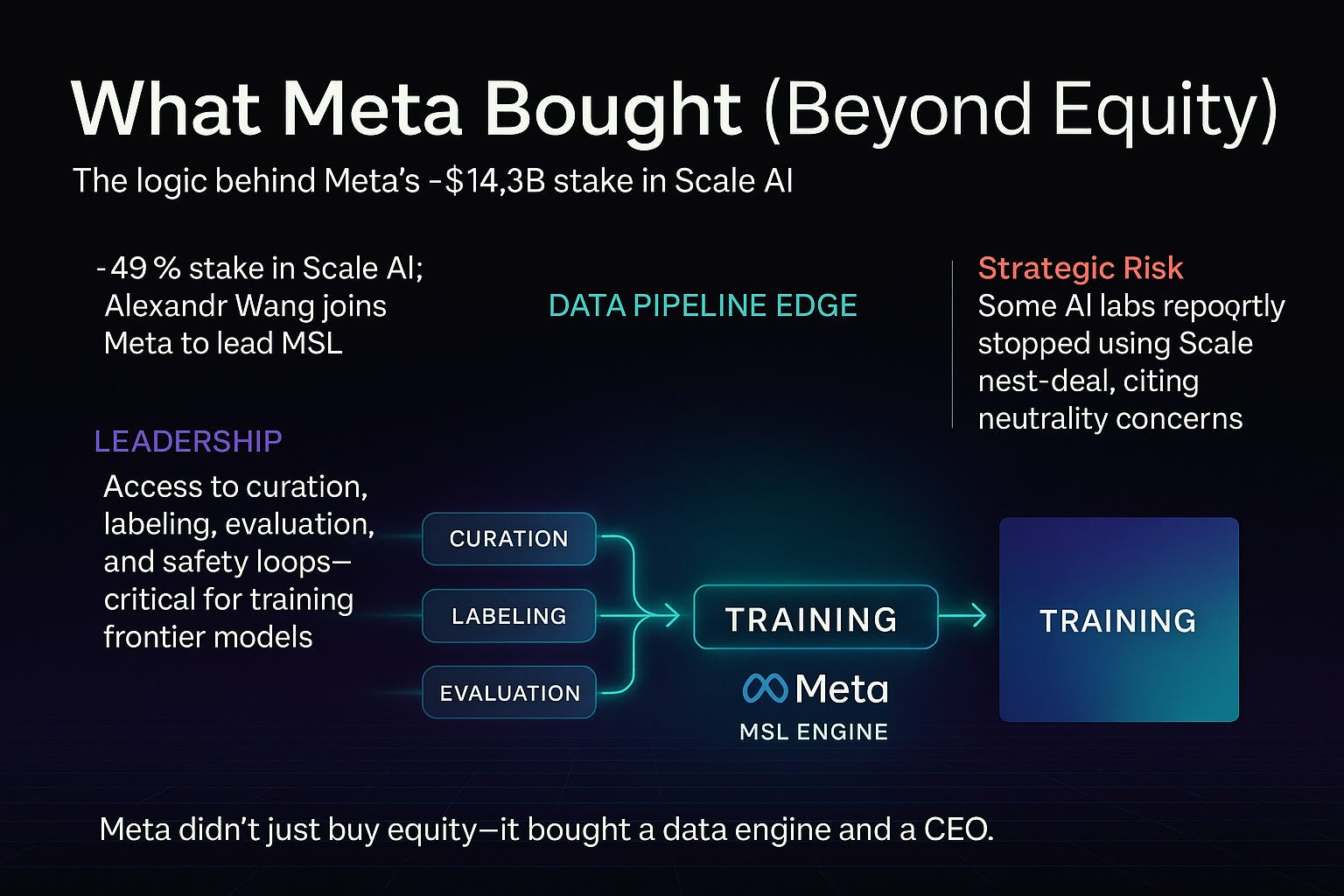
After years of playing catch-up to OpenAI, Google DeepMind, and Anthropic, Meta hit reset with a $14.3 billion play: buying nearly half of Scale AI and installing its founder Alexandr Wang at the helm of Meta Superintelligence Labs (MSL).
It wasn’t just about models. It was about building a machine—a new kind of AI lab that combined talent density, data pipelines, and compute infrastructure at unprecedented scale.
But what makes this story explosive isn’t just the dollars—it’s the headhunting war Meta ignited, offering packages in the hundreds of millions (even up to $1B) to pry away top researchers from OpenAI, DeepMind, and Anthropic.
The Trigger: Why Meta Hit Reset
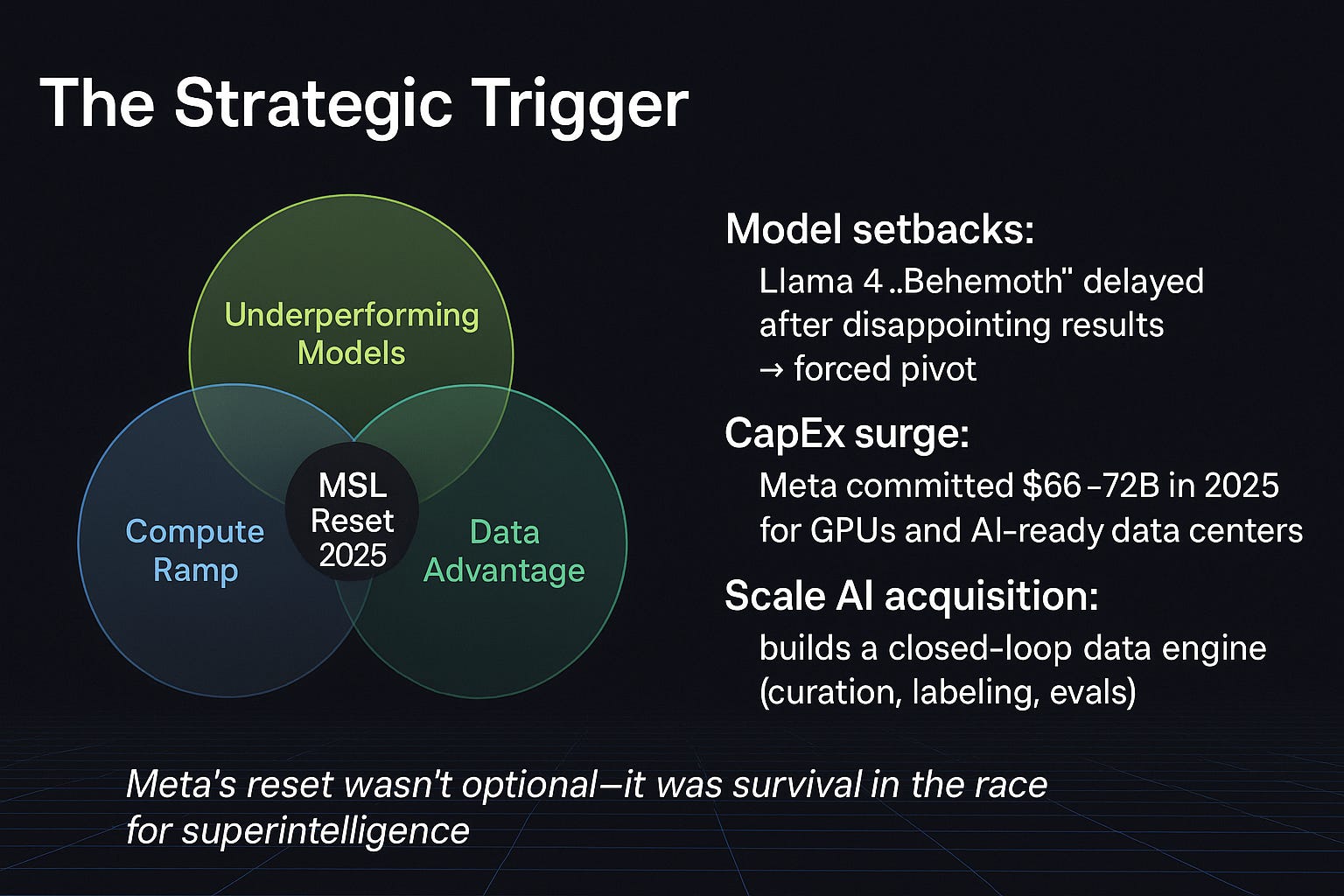
Meta’s pivot wasn’t voluntary. It was forced.
Model setbacks: Llama 4 “Behemoth” underperformed and was delayed, leaving Meta behind in frontier model quality (WSJ).
CapEx escalation: In 2025, Meta committed $66–72B in capital expenditures—largely AI infrastructure. For context, this rivals the annual R&D budgets of entire industries (Reuters).
Data bottleneck: Scale AI’s data pipelines (curation, labeling, evaluation) gave Meta what it lacked: a closed-loop data engine (TechCrunch).
In short, weak models, rising spend, and data gaps converged. The only path forward: buy speed with talent and infrastructure.
The Market Prize: Why $14B Could Be a Bargain
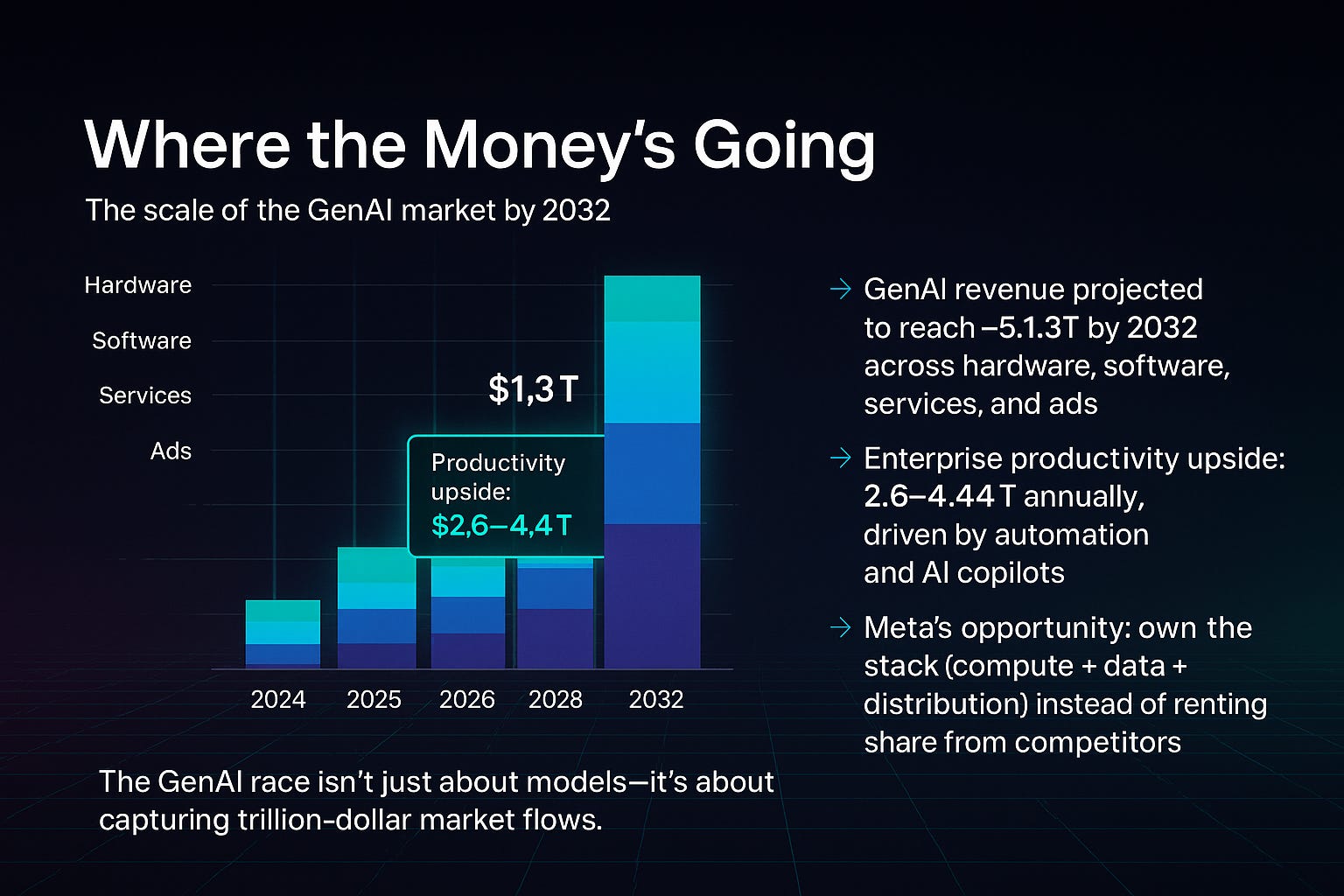
Why risk billions? Because the stakes dwarf the investment.

GenAI market: Forecast to reach $1.3 trillion by 2032, spanning hardware, software, services, and ads (Bloomberg Intelligence).
Productivity upside: McKinsey estimates $2.6–$4.4 trillion annually in enterprise gains from GenAI copilots and automation (McKinsey).
Meta’s advantage: Unlike rivals, Meta already owns the largest consumer distribution surfaces—Facebook, Instagram, WhatsApp. If it closes the model quality gap, it can monetize across billions of users instantly.
The Scale AI stake is a down payment on that vision.
The Talent War: Headhunting at Billion-Dollar Scale
Unprecedented Offers
What made headlines wasn’t just Meta’s infrastructure—it was the aggressive pursuit of elite researchers:
Meta dangled packages worth hundreds of millions to nearly $1 billion to lure top scientists from OpenAI, DeepMind, and Anthropic (Business Insider).
These offers included cash, stock grants, and long-term bonuses tied to superintelligence milestones.
Even smaller independent labs (e.g., Thinking Machines Lab) reported turning down nine-figure offers—suggesting that vision, not money, is the true differentiator.
Key Hires
Alexandr Wang (Scale AI) → now Chief AI Officer at Meta.
Nat Friedman (ex-GitHub CEO) → co-leading applied research and product integration.
Researchers from Apple, DeepMind, OpenAI, Anthropic were courted, with some accepting, many rejecting.
The Retention Problem
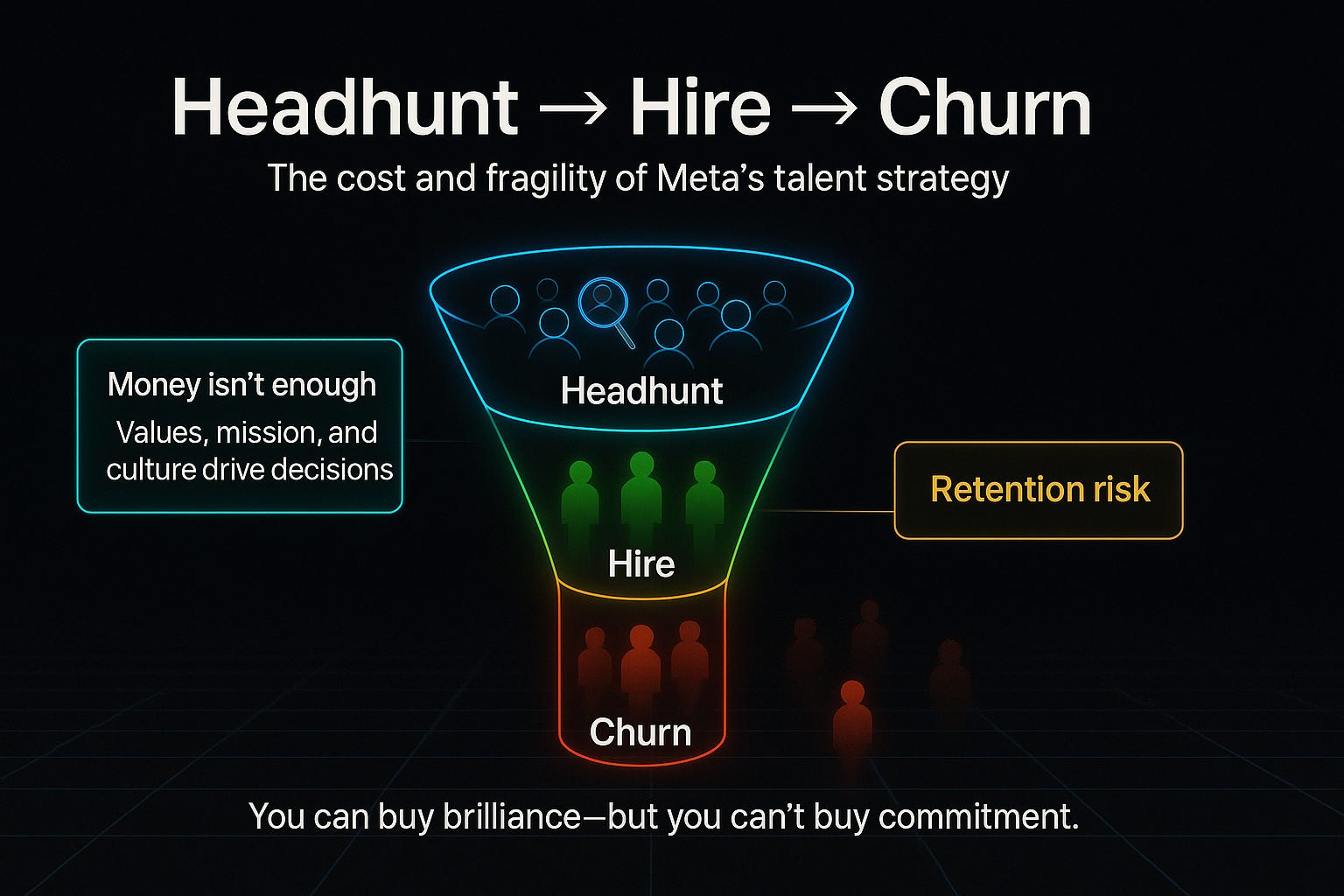
But here’s the catch: some hires have already quit within months, citing cultural misalignment, bureaucracy, or lack of clarity around Meta’s mission (WIRED).
Talent is a double-edged sword:
Acquiring brilliance is easy with capital.
Keeping brilliance requires mission, culture, and trust.
Meta risks building the most expensive revolving door in Silicon Valley if retention doesn’t match recruitment.
The Organizational Reset: MSL as a Skunk-Works
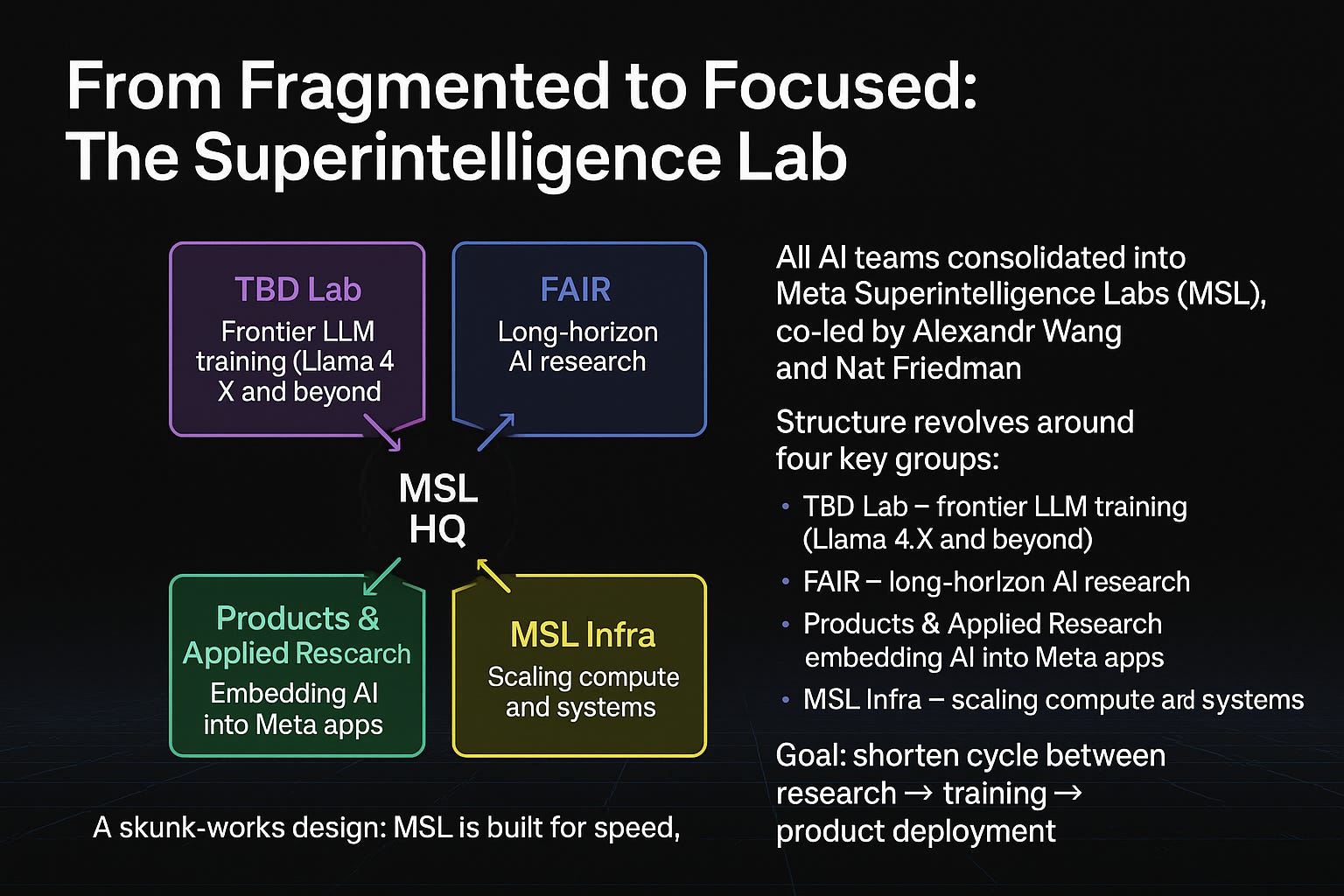
To house this talent, Meta reorganized into Meta Superintelligence Labs, split into four core groups (The Verge):
TBD Lab → frontier training, Llama 4.X and beyond.
FAIR → long-horizon AI research.
Products & Applied Research → embedding AI into consumer apps.
MSL Infra → compute, systems, and infra scaling.
This structure mirrors defense “skunk-works” labs: small, elite teams tasked with breakthrough innovation.
Compute as a Moat: Buying Time with Silicon
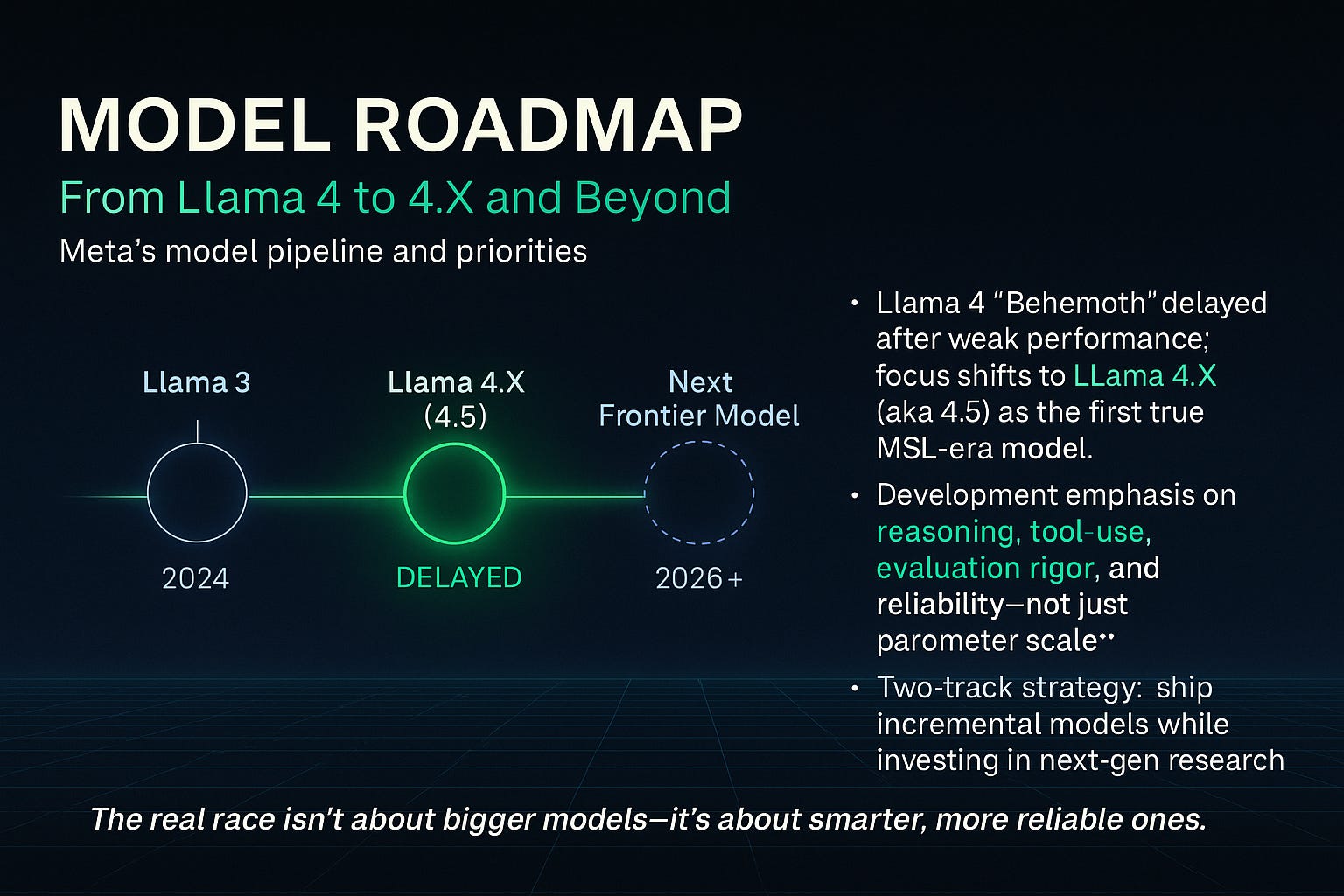
Meta is also amassing the largest compute arsenal in the world:
Targeting 350k H100s (~600k equivalents) deployed by end-2024 (SemiAnalysis).
Building the Louisiana AI Campus as a new hub for model training.
Spending $66–72B annually to scale infra.
This isn’t just about GPUs. It’s about buying faster training cycles, giving researchers more shots on goal.

But as one rival put it:
“You can’t brute-force your way to superintelligence with GPUs alone. You need the people who know how to use them.”
Product Pragmatism: Borrow Now, Build Later

While its own models lag, Meta has considered integrating Google Gemini or OpenAI GPT models into apps (Reuters).
This may look like weakness. In reality, it’s pragmatism:
Protect user experience today.
Buy time for MSL to deliver.
Keep users on Meta surfaces instead of bleeding to competitors.
It’s a bridge strategy: Borrow now → Build later.
The Risks: What Could Break the Story
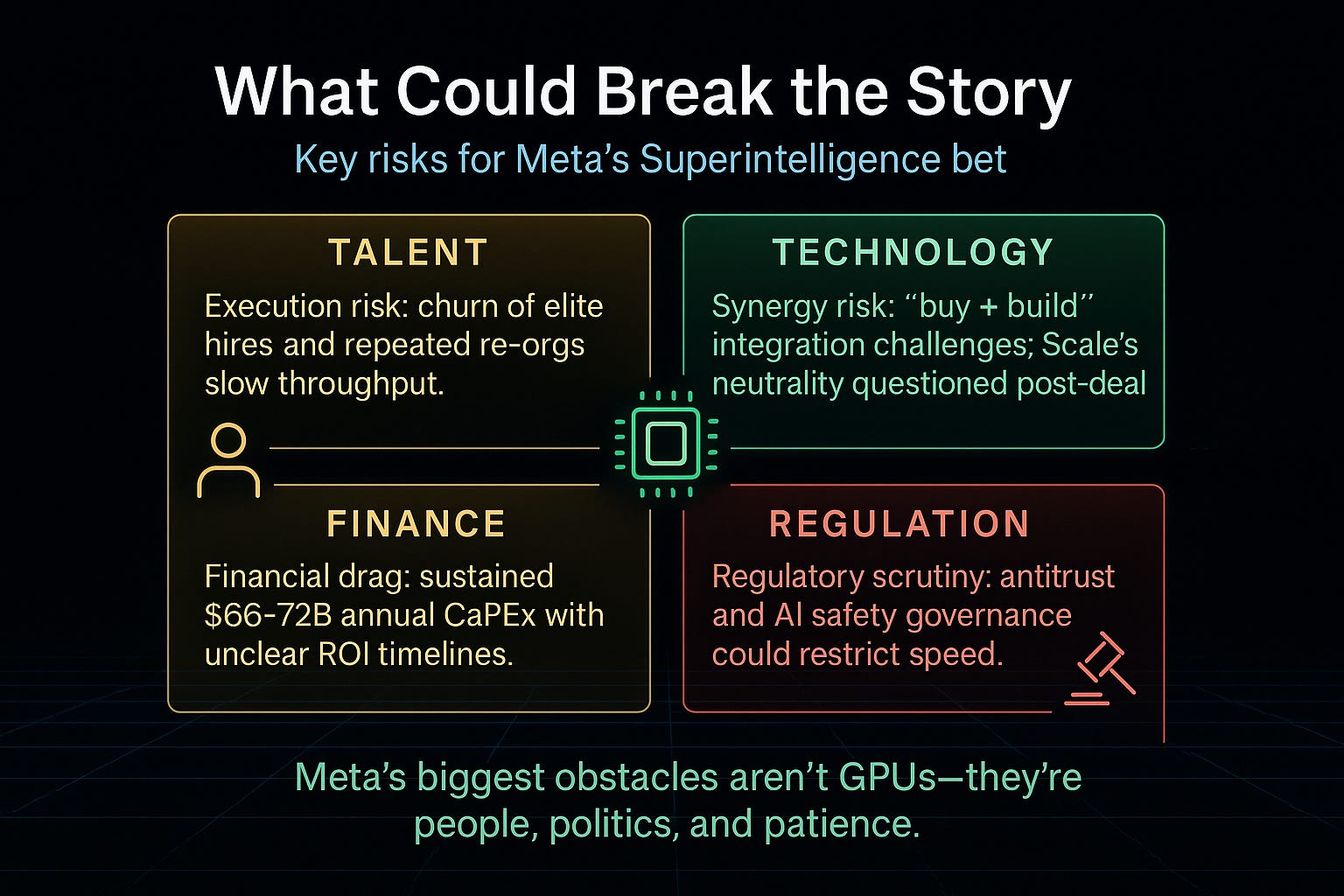
Meta’s bet is bold. But several risks loom:
Execution risk: talent churn, re-org fatigue.
Synergy risk: integration friction with Scale AI.
Financial drag: $66–72B annual CapEx with uncertain ROI timelines.
Regulation: antitrust and AI safety scrutiny could restrict speed.
The hardware is solvable. The human and political factors may not be.
Scenarios: 2026 Futures
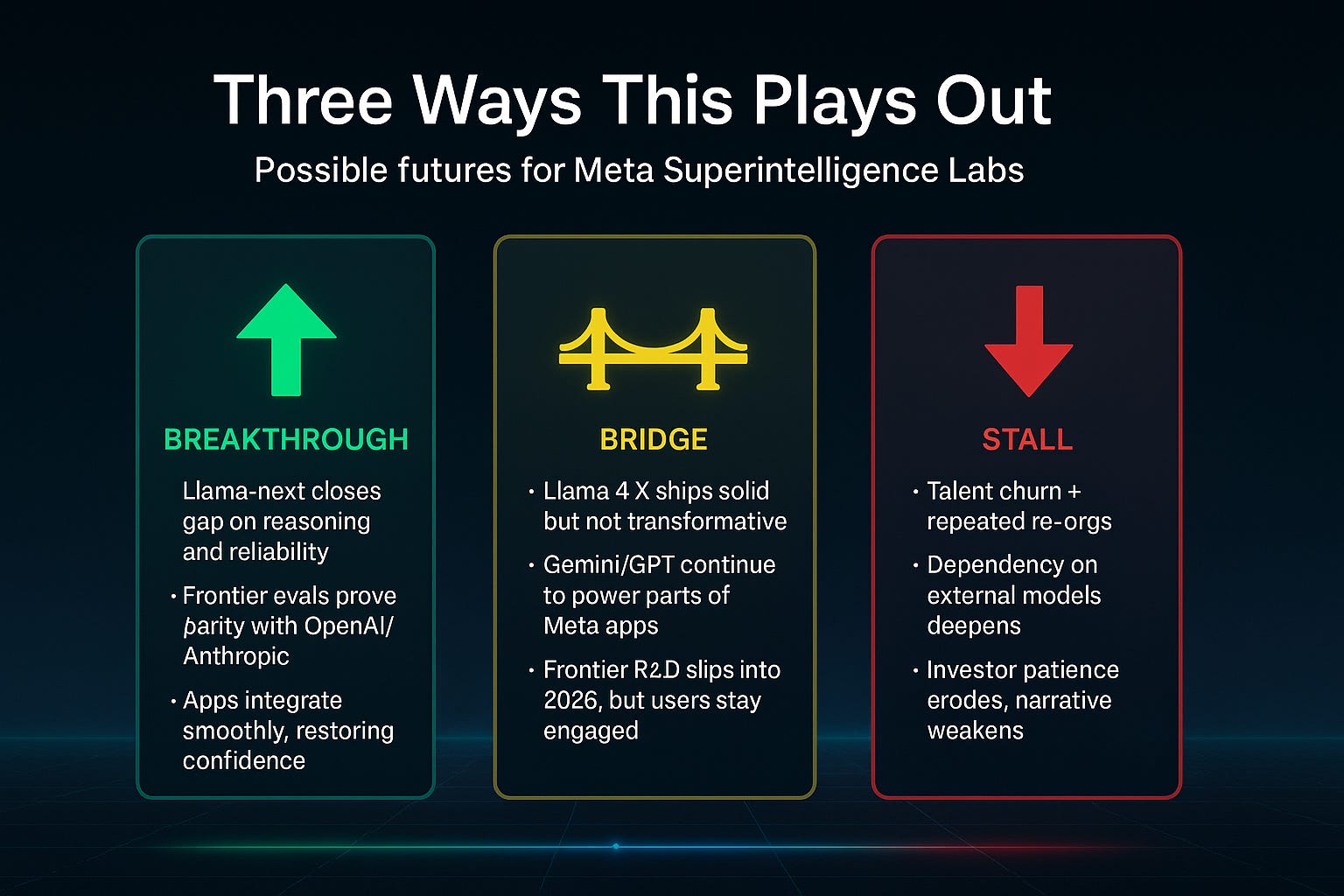
Breakthrough (Green): Llama-next achieves reasoning parity, apps integrate seamlessly, Meta reclaims credibility.
Bridge (Amber): Llama 4.X ships solid but not transformative, with external models filling gaps. Frontier R&D slips to 2026.
Stall (Red): Talent churn accelerates, dependence on Gemini/GPT deepens, investor patience erodes.
The outcome depends less on GPUs—and more on execution, culture, and timing.
Executive Takeaways

Talent-first isn’t enough → Retention and mission clarity are existential.
Infrastructure is necessary but insufficient → Compute buys time, not outcomes.
Borrowing models is smart pragmatism → UX now, frontier breakthroughs later.
The market prize is massive → $1.3T+ GenAI upside awaits whoever aligns compute, data, and distribution.

Final Thought:
Meta’s gamble is audacious. But history shows: money can buy GPUs and people—vision keeps them there.